基于Token Expansion的高效Transformer训练方法
A General and Efficient Training for Transformer via Token Expansion

- 作者投稿到CVPR2024
- 公开代码
Motivation
- 现有训练加速方法容易使得模型准确率降低
- 现有训练加速方法破坏了原来transformer的参数训练一致性
- 通用性不足,现有部分加速方法利用了额外的训练策略加速或是修改了模型结构,无法很好的适应通用模型
Contribution
- 提出了ToE加速训练方法,能够很好得嵌入transformer训练方法中,而不会影响transformer训练一致性
- 提出了"initialization-expansion-merging"框架避免token信息丢失
- 实验证明ToE优于之前的SOTA方法
ToE方法
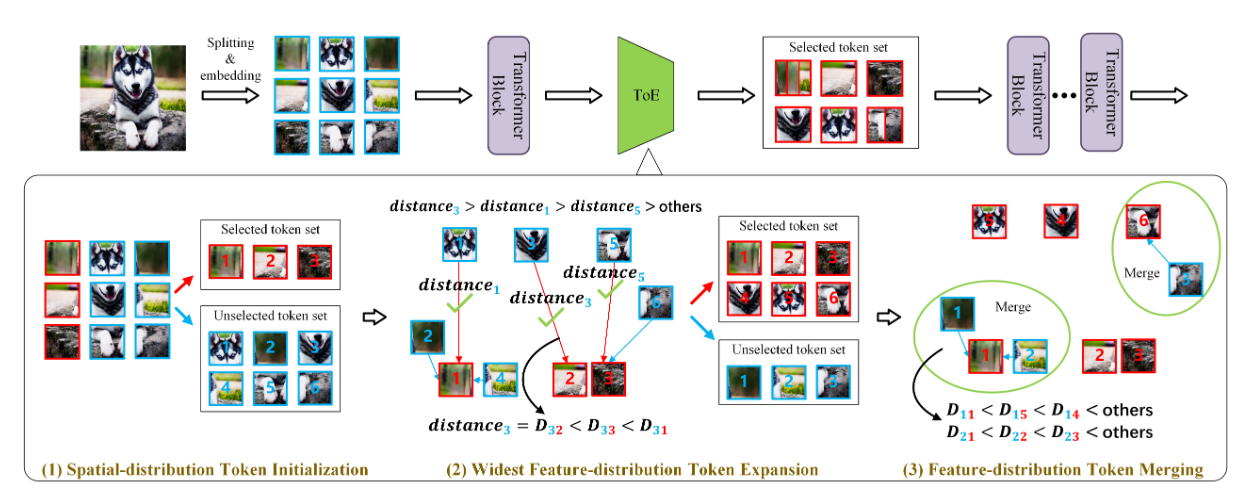
ToE方法分为三个阶段
- step 1:初始token选择
根据保留率 从每$\left\lfloor \frac{1}{r_0} \right\rfloor$样本中选择出要保留的选择token
- step 2:Token Expansion
在处理的每个阶段都会逐步增加token的数量,是一种 grow token number的思想来保证特征不会丢失的太多。类似于另外一种稀疏注意力
$$
\mu_{\delta} = \begin{cases}
r_1 - r_0, & \text{if } \delta = 1, \
\frac{1 - r_1}{N_g - 1}, & \text{otherwise}
\end{cases}
$$
$$
r_{\delta} = r_{\delta - 1} + \mu_{\delta}
$$
在每个阶段都会增加对应 $\mu_{\delta}$比例的token数量
更新方法为使用余弦相似度,来寻找与已选择token集距离最远的token来达到增加token表示能力的目的
$$
distance=\mathcal{D}(\mathbf{B}, \mathbf{A}) = 1 - \cos\langle \mathbf{B}, \mathbf{A} \rangle = 1 - \frac{\mathbf{B} \mathbf{A}^\top}{|\mathbf{B}| \cdot |\mathbf{A}|}
$$
- step 3: Token特征合并
在Token扩展阶段结束后,还会有部分unselected token的特征信息没有被充分利用。为了利用这部分的特征形象,会选择离unselected token 最近的selected token,将他们利用平均值进行特征合并
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Peak!