基于Token Expansion的高效Transformer训练方法
A General and Efficient Training for Transformer via Token Expansion
作者投稿到CVPR2024
公开代码
Motivation
现有训练加速方法容易使得模型准确率降低
现有训练加速方法破坏了原来transformer的参数训练一致性
通用性不足,现有部分加速方法利用了额外的训练策略加速或是修改了模型结构,无法很好的适应通用模型
Contribution
提出了ToE加速训练方法,能够很好得嵌入transformer训练方法中,而不会影响transformer训练一致性
提出了"initialization-expansion-merging"框架避免token信息丢失
实验证明ToE优于之前的SOTA方法
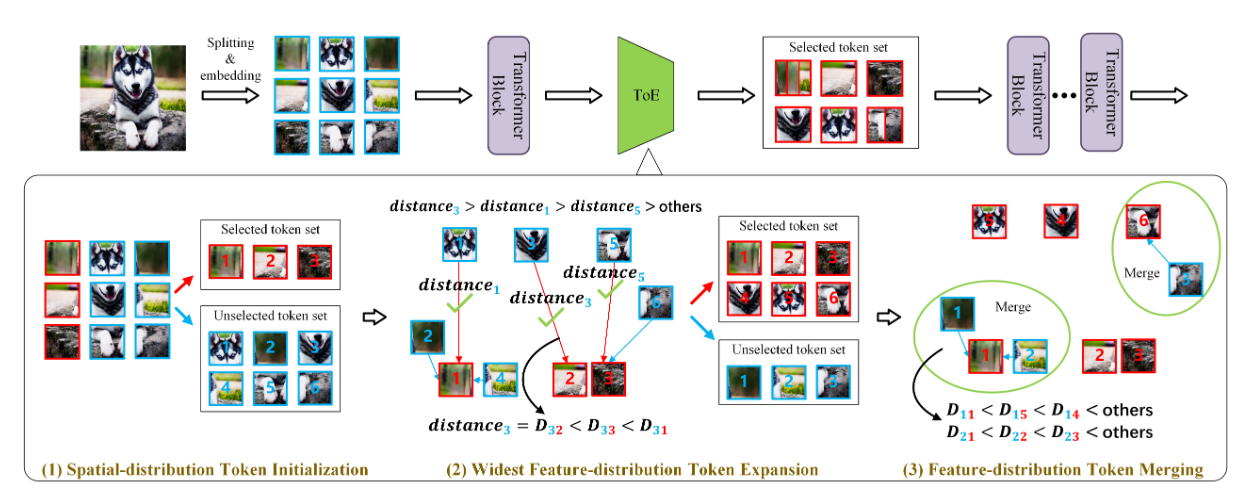
ToE方法
ToE方法分为三个阶段
step 1:初始token选择
根据保留率 从每$\left\lfloor \frac{1}{r_0} \right\rfloor$样本中选择出要保留的选择token
step 2:Token Expansion
在处理的每个阶段都会 ...
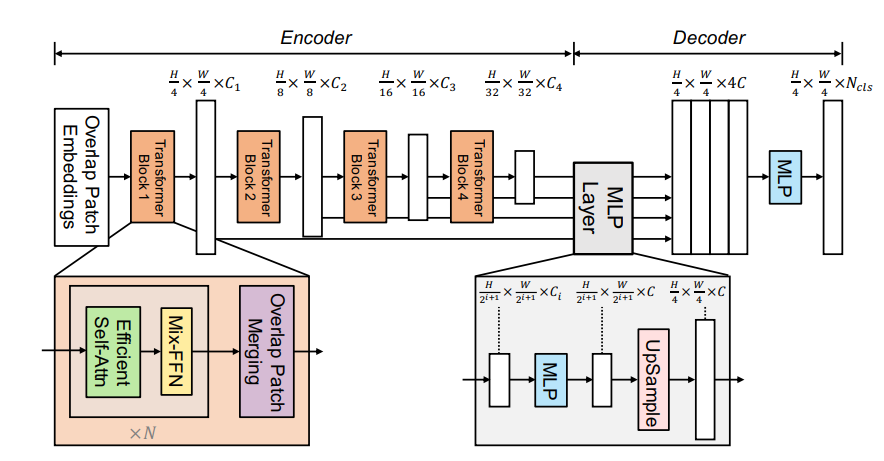
SegFormer网络模型
SegFormer
网络模型
可以看到网络使用多层Transformer作为Encoder,使用MLP作为decoder
创新点
SegFormer包含一个新颖的层次结构的Transformer编码器,它输出多尺度特征。它不需要位置编码,从而避免了位置编码的插值问题,当测试分辨率与训练不同时,导致性能下降。
SegFormer避免了复杂的解码器。提出的MLP解码器从不同层级聚合信息,从而结合了局部注意力和全局注意力,以生成强大的表示。
Overlap Patch Merging
Overlap Patch Merging是一种图像处理技术,用于将重叠的图像块合并成为一个完整的图像。 在图像处理中,将图像分成小块进行处理可以带来一些好处,比如降低计算复杂度、提高处理效率等。然而,当图像块之间存在重叠时,需要将它们合并起来以恢复图像的完整性。 Overlap Patch Merging的过程通常包括以下步骤:
划分图像:将原始图像划分成重叠的块。这些块通常有固定的大小,并且相邻块之间有一定的重叠区域。
特征提取:对每个图像块进行特征提取,可以使用各种图像特征提取方法,如卷积 ...
DC-swin网络模型
DC-swin
网络结构
网络结构依然是传统的Unet模型
主干网络部分使用swin-Transformer来提取上下文特征
下采样
在跳跃连接部分,除了stage阶段Swin-s模块的下采样
网络还使用了传统卷积的方法下采样来补充丢失信息
空间注意力计算
通道注意力计算
上采样
上采样部分采用传统的转置卷积恢复
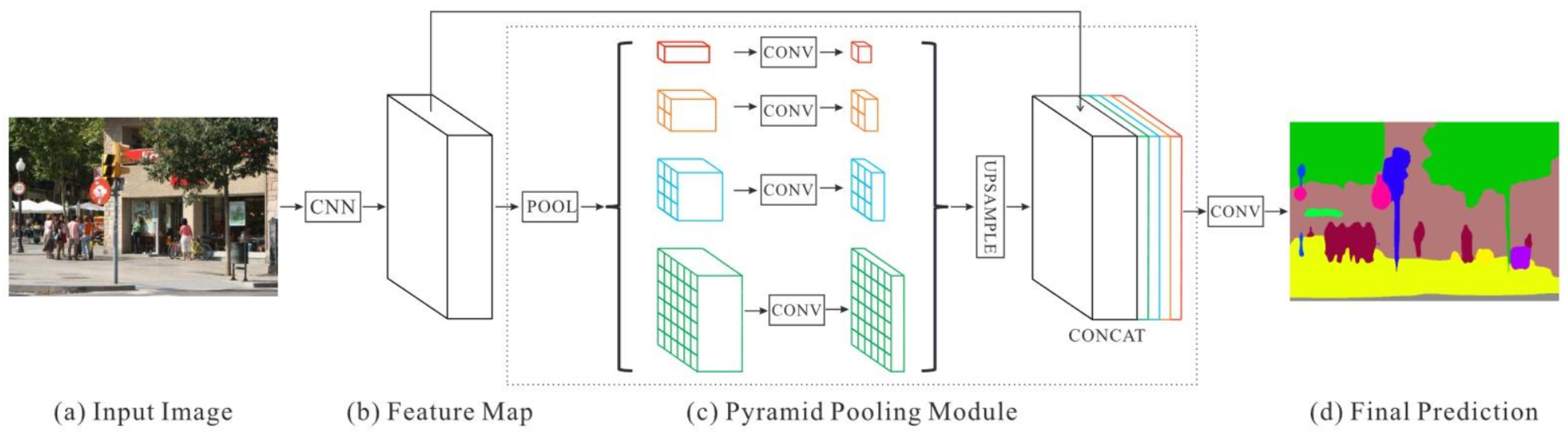
PSPNet网络模型
PSPNet
发现其实看的论文也不少了,但是有点不善于总结。经常性看过就忘掉了,以后得常看常总结了。
用MMsegmentation跑了一下这个模型,学习记录一下。
网络结构
PSPNet的核心思想是金字塔平均池化来捕捉不同尺度的上下文信息。
从©部分可以看出论文的主要工作。池化之后经过上采样恢复图像。
从(a)到©的backbone使用Resnet,并加入了空洞卷积
金字塔池化
PSPNet的核心部分是金字塔池化模块,用于捕捉不同尺度上的上下文信息。该模块首先对主干网络提取的特征图进行多个不同尺度的池化操作,以获取不同感受野的信息。常见的池化操作包括平均池化或最大池化。每个池化操作产生一个固定大小的特征图。
融合和上采样
将经过池化操作得到的特征图进行级联或逐元素相加的方式进行融合。这样可以将不同尺度上的上下文信息整合到一个特征图中。为了将融合后的特征图恢复到原始图像的尺寸,使用反卷积或插值等技术进行上采样操作。这样可以将低分辨率的特征图映射回输入图像的分辨率,得到像素级别的分割结果。
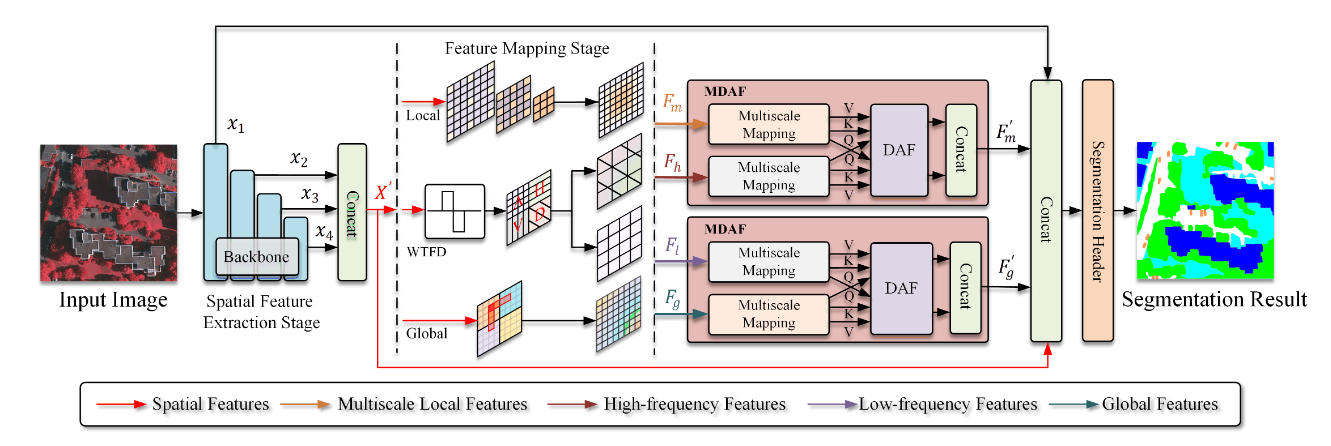
SFFNet-基于小波空间域和频率域的融合网络
SFFNet
创新点
引入了小波变换特征器,分解空间的高频和低频信息,有效利用频域信息
设计多尺度双表示对齐滤波器实现了频域和空间域特征对齐与选择,并进一步分割特征
网络结构
Stage one (ConvNext)
使用卷积操作提取图像空间特征,经过三次下采样提取,将最后三次卷积得到的不同尺度的特征处理后concat连接。
$X’=Cat(\delta_{1\times1}(\varphi(x_2)),\delta_{1\times1}(\varphi(x_3)),\delta_{1\times1}(\varphi(x_4)))$
$X’$作为原始输入到后续阶段二的多分枝中进行处理
Stage two(Feature Mapping)
Global Branch
在全局分支中,首先使用3x3卷积下采样输入特征,之后使用W-Trans块来划分窗口计算窗口注意力和建立窗口间关联。不同于SW-Trans中的方法,该划分采用垂直窗口卷积的方式建立关联。
Local Branch
...

随笔-02
随笔-02
此时此刻,一个人在宿舍,想找对象的心情达到了顶峰0.0
自己宿舍和隔壁宿舍就剩自己,突然有点讨厌放假。
本科的时候宿舍有四条单身狗,也都是宅男性格,一到放假就在宿舍打游戏,其他宿舍的同学也是,所以一点都不无聊。每次寒暑假放假甚至会晚一点儿走,为了留在学校和朋友们玩。
回到正题,想想这周的科研情况,看了看代码,大致能看懂了,以后配合GPT应该也能自己开始写了,希望研一能够顺利发论文吧。
其实这周最开心的是组里的同学给我介绍了个女同学,是他的本科同学。终于加上女生了,蕾姆55555
感觉女生性格也挺好,山东人,跟我聊天也挺热情的,希望能有结果吧。万一瞧不上咱也没事,毕竟咱也不是彭于晏。。。。要学会坦然接受失败。
还有就是,自己把椅子换掉了,骚哥亲情推荐。149元晒图还能返20,下次去实验室得拍照返图QAQ。去实验室的动力也足了,就是科研上不清楚自己要干嘛效率高点,每天都是自己凑合着学学。
为啥想找对象了呢。。。。一方面是峰爷一直催我,我也觉得很有道理。另一方面是国庆中秋就我一个人在宿舍,这您受得了吗?加上有点电子阳痿,玩游戏也提不起劲,可能因为我现在太强了,但是身边朋友没有和我 ...
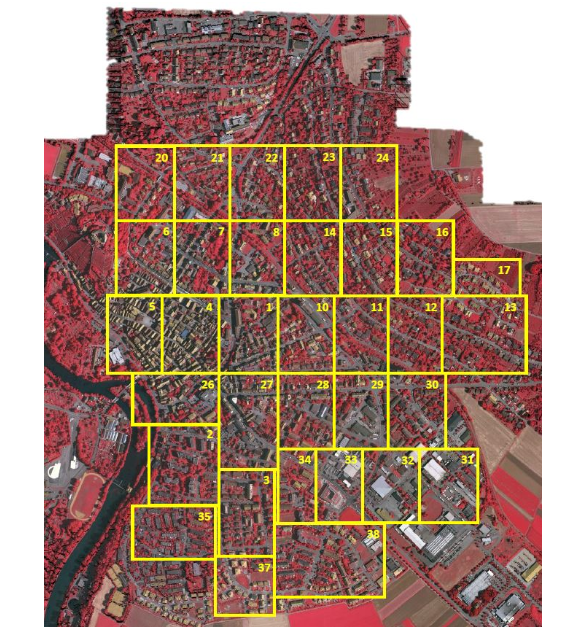
vaihingen数据集介绍与使用
vaihingen数据集
ISPRS Vaihingen Dataset 是国际摄影测量与遥感学会(ISPRS)发布的一个用于评估遥感图像语义分割和目标识别算法的标准数据集。该数据集主要覆盖了德国瓦伊因根(Vaihingen)地区的高分辨率航空影像,广泛用于遥感、地理信息系统(GIS)、城市规划、环境监测等领域的研究和应用。
数据集将区域划分为了33个patch,如上图所示,编号不是连续的
图像类型: 高分辨率航空影像,提供了3个波段:红外(IR)、红(R)和绿(G),因此是一个近红外-红-绿(IRRG)组合图像。
分辨率: 影像的空间分辨率为 9cm/pixel,这意味着每个像素代表地面上 9 厘米见方的区域,数据的精细度非常高。
地区覆盖: 数据集覆盖了Vaihingen的部分城区,包含住宅区、工业区、绿地、道路和河流等多种地表类型。
地面真值(Ground Truth)标注:
数据集提供了经过人工标注的地面真值,这些标注被细分为不同的地物类别,包括:
建筑物 (Buildings)
树木 (Trees)
低植被 (Low Vegetation)
道路 (Roads)
汽 ...
UnetFormer代码解析
网络结构
从代码层面理解UnetFormer的具体实现是过程中的图像维度变化。窗口机制的实现原理,跳远连接的操作。
1234567891011121314151617181920212223242526class UNetFormer(nn.Module): def __init__(self, decode_channels=64, dropout=0.1, backbone_name='swsl_resnet18', pretrained=True, window_size=8, num_classes=6 ): super().__init__() self.training = False self.backbone = timm.create_model(backbone_name, f ...

无聊的随笔-01
随笔-01
其实很久没有写博客了。。。
网站是2021年运营的,但是能看到文章都是今年写的。因为之前文章的图片放在新浪图床里,之后新浪图床应该是不对外访问了,导致原本文章的图片全部崩掉了。
其实也未尝不是一件好事吧。暴雷早了还能少点损失,现在用自己的图床了,只要github不崩,图床就不会炸。
感觉大四好像一直在摆,虽然考上研了,但只能说是学校收留我,遇到了很好的导师。摆了这么久,玩累了,想想还是学习吧。毕竟导师比我还努力,没理由玩了啊。
计划是每周写一篇随笔记录反思一下,没对象只能写博客发发牢骚了QAQ。
研究生入学了。
室友是本科朋友,完美,开学一两周也没啥事儿,实验室氛围也挺好。
峰爷说的对:创造美好实验室条件让大家自愿来实验室才是正确的。我是非常自愿的,若是能把师兄传承给我的破椅子换了,我想我应该会更自愿了,毕竟,当我躺在椅子上的时候,旁人看我大抵是潇洒惬意的,但其实是椅子靠不住啊。
得多多反思。
感觉在学校呆久了,有时候已经变得不像自己了。学生思维限制了自己,应该多读读书才好。
多看多听多观察,跟导师出门还是不够狗腿啊,感觉自己情商还是不高。。。。倒不是说拉不下了,而是习惯了 ...
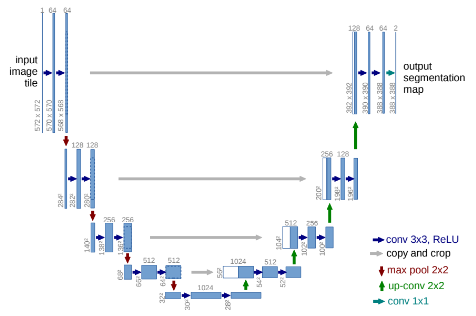
U-Net网络模型
U-Net网络
网络结构
从网络结构上,整个结构以编码器-解码器结构呈现U形模式。
网络中输入部分由于卷积操作,导致图像尺寸发生变化,这点可以使用padding避免,卷积增加了原始图像的通道数,经过池化后图像尺寸进一步压缩达到下采样目的,不断经过卷积池化下采样后到达网络底部。
继续卷积加上采样进行解码恢复信息,采用转置矩阵的方法进行上采样。在这一部分会与编码处理部分的图像进行concat连接,由于原始图像和当前图像的尺寸不匹配,会采用crop剪切以匹配大小。之后上采样恢复图像,并使用卷积降低通道数,得到最后背景和样本的双通道输出。输出图像和输入图像的尺寸也不是相同的。
Overlap
在进行图像处理时,对图像处理进行划分处理减轻显存压力,由于划分区域的边界信息不充足,在划分时不尽准确。因此划分时图像边界使用重叠划分以提高准确率。对于图像边界缺失部分采用镜像操作提高准确度。
边界错误权重
在细胞划分时,细胞边界不易区分。采用提高细胞边界误差权重的方法增加损失函数来加强边界划分的能力。