UnetFormer代码解析
网络结构
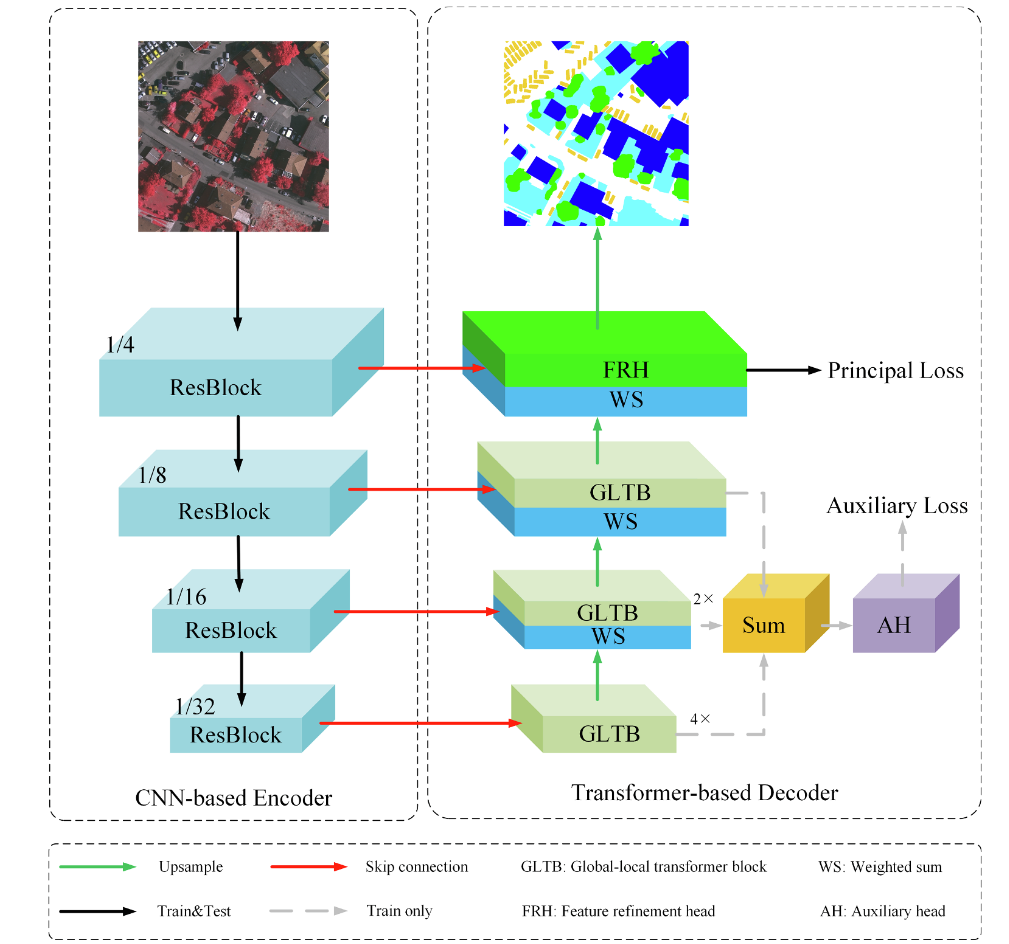
从代码层面理解UnetFormer的具体实现是过程中的图像维度变化。窗口机制的实现原理,跳远连接的操作。
1 | class UNetFormer(nn.Module): |
该代码定义了网络的主干结构,使用timm库构建了四层ResNet18主干网络。并以编码器-解码器的结构构建整个网络框架。
编码器
编码器的主体结构使用timm库构建,并使用feature_info参数获取不同层次的通道数参数。
解码器
1 | def forward(self, res1, res2, res3, res4, h, w): |
解码器结构由GLTB块和WS块初步处理,并在过程中将编码器的三层残差经过处理后进行上采样sum
GLTB
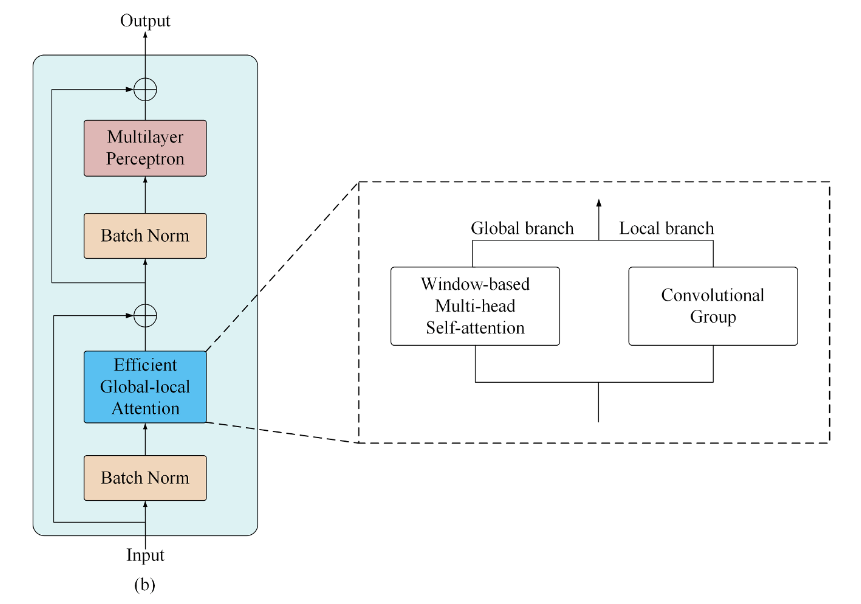
1 | class Block(nn.Module): |
网络结构由两阶段的注意力和多层感知机处理结果与原始输入相加实现。
全局局部注意力
-
局部注意力
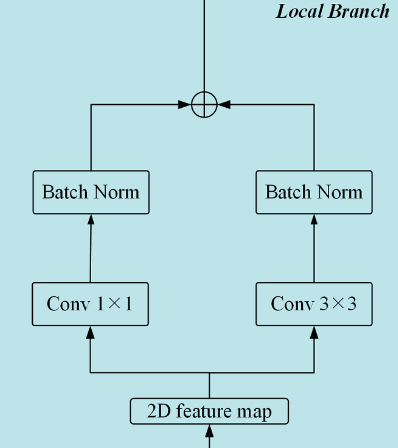
1
2self.local1 = ConvBN(dim, dim, kernel_size=3)
self.local2 = ConvBN(dim, dim, kernel_size=1 -
全局注意力
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37def forward(self, x):
B, C, H, W = x.shape
local = self.local2(x) + self.local1(x)
x = self.pad(x, self.ws)
B, C, Hp, Wp = x.shape
qkv = self.qkv(x)
q, k, v = rearrange(qkv, 'b (qkv h d) (hh ws1) (ww ws2) -> qkv (b hh ww) h (ws1 ws2) d', h=self.num_heads,
d=C // self.num_heads, hh=Hp // self.ws, ww=Wp // self.ws, qkv=3, ws1=self.ws, ws2=self.ws)
dots = (q @ k.transpose(-2, -1)) * self.scale
if self.relative_pos_embedding:
relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.ws * self.ws, self.ws * self.ws, -1) # Wh*Ww,Wh*Ww,nH
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
dots += relative_position_bias.unsqueeze(0)
attn = dots.softmax(dim=-1)
attn = attn @ v
attn = rearrange(attn, '(b hh ww) h (ws1 ws2) d -> b (h d) (hh ws1) (ww ws2)', h=self.num_heads,
d=C // self.num_heads, hh=Hp // self.ws, ww=Wp // self.ws, ws1=self.ws, ws2=self.ws)
attn = attn[:, :, :H, :W]
out = self.attn_x(F.pad(attn, pad=(0, 0, 0, 1), mode='reflect')) + \
self.attn_y(F.pad(attn, pad=(0, 1, 0, 0), mode='reflect'))
out = out + local
out = self.pad_out(out)
out = self.proj(out)
# print(out.size())
out = out[:, :, :H, :W]
return out
将输入特征升维3倍通道数,使用rearrange将输入数据展平到窗口化维度,并展平一维化后计算各自头的注意力得分。之后将注意力得分进行相对位置嵌入捕获特征间的位置关系,经过softmax处理后与值相乘得到最后的自注意力矩阵。
之后使用横向和纵向的两个池化操作进一步提取特征。
最后将局部与全局注意力特征融合
WS权重分配
该模块权重融合残差和输入特征
1 | class WF(nn.Module): |
- 上采样输入特征图
- 权重relu激活和归一化处理
- 特征加权融合
FRH特征修复头
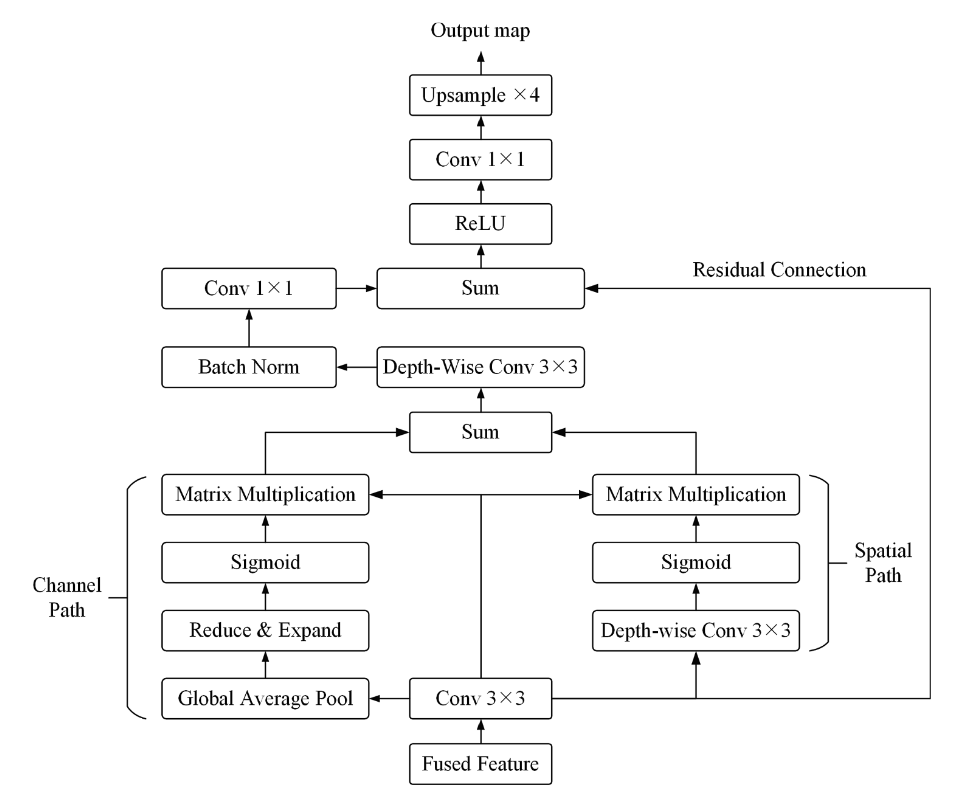
1 | class FeatureRefinementHead(nn.Module): |
将输入特征上采样之后与原始残差加权融合,之后使用双分支结构分别处理通道和空间信息。通道信息利用全局池化提取,空间信息使用卷积提取。将结果sum融合后经过卷积处理与shortcut剪切后大小相同的残差原始信息融合。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Peak!